









机器学习基础 | 监督学习与无监督学习的快速入门指南
介绍监督学习和无监督学习有什么区别?
对于机器学习的初学者和新手来说,这是一个常见的问题。答案是理解机器学习算法本质的核心。如果没有明白监督学习与无监督学习之间的区别,你的机器学习之旅就无法继续进行。实际上,这是你踏上机器学习之旅之初应该学习的东西。如果我们不了解线性回归,逻辑回归,聚类,神经网络等算法的适用范围,就不能简单地跳到模型构建阶段。
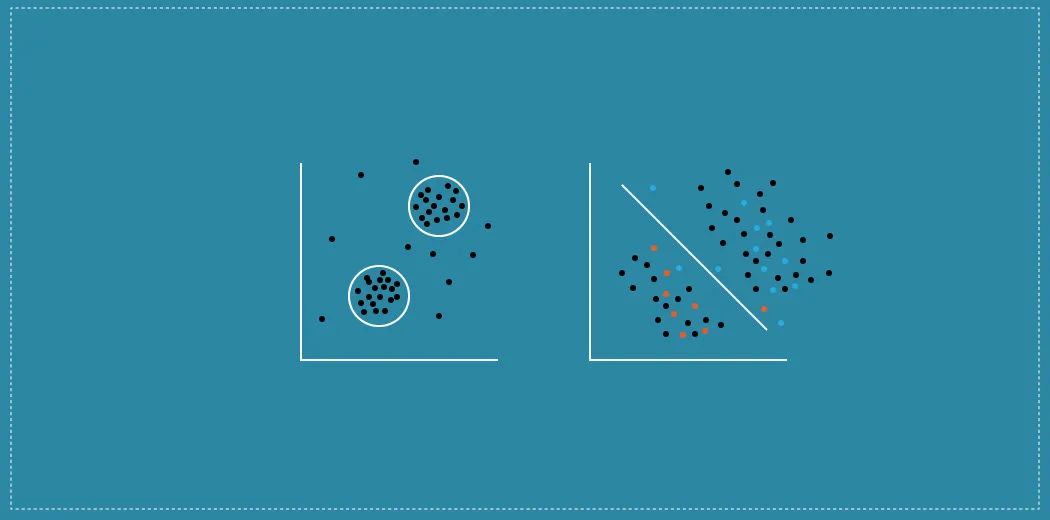
如果我们不知道机器学习算法的目标是什么,我们将无法建立一个准确的模型。这就是监督学习与无监督学习的由来。在这篇文章中,我将用例子讨论这两个概念,并回答一个大问题——如何决定何时使用监督学习或非监督学习?什么是监督学习?在监督学习中,计算机是通过数据来训练的。它从过去的数据中学习,并将学习到的东西应用到现在的数据中,以预测未来的事件。在这种情况下,输入数据和期望的输出数据都为预测未来事件提供帮助。为了准确预测,输入数据被标记了正确的类别。

监督机器学习分类重要的是要先记住,所有有监督学习算法本质上都是复杂的算法,分为分类或回归模型。1) 分类模型:分类模型用于输出变量可以分类的问题,例如“是”或“否”、“通过”或“失败”。分类模型用于预测数据的类别。现实生活中的例子包括垃圾邮件检测、情绪分析、考试记分卡预测等。2) 回归模型:回归模型用于输出变量为实际值的问题,例如唯一的数字、美元、工资、体重或压力。它通常用于根据先前的数据观测预测数值。一些比较常见的回归算法包括线性回归、logistic回归、多项式回归和岭回归。

监督学习算法在现实生活中有一些非常实际的应用,包括:文本分类人脸检测签名识别客户发现垃圾邮件检测天气预报根据当前市场价格预测房价股票价格预测等什么是无监督学习?另一方面,无监督学习是训练机器使用既没有分类也没有标记的数据的方法,这意味着不能提供任何训练数据,机器只能自己学习。机器必须能够对数据进行分类,而无需事先提供任何有关数据的信息。其思想是将机器暴露在大量变化的数据中,并允许它从这些数据中学习,以提供以前未知的见解,并识别隐藏的模式。因此,没有必要定义无监督学习算法的结果,相反,它确定了与给定数据集不同或有趣的内容。这台机器需要编程才能自动学习。计算机需要理解结构化和非结构化数据。以下是无监督学习的精确说明:

1)聚类是最常见的无监督学习方法之一。聚类的方法包括将未标记的数据组织到称为聚类的集群中。因此,集群是类似数据项的集合。这里的主要目标是发现数据点之间的相似性,并将相似的数据点分组到一个集群中。2)异常检测是指识别与大部分数据有显著差异的稀有项、事件或观测值的方法。我们通常在数据中寻找异常或异常值,因为它们是可疑的。异常检测常用于银行诈骗和医疗差错检测。无监督学习算法的应用无监督学习算法的一些实际应用包括:欺诈检测恶意软件检测数据输入过程中人为错误的识别进行精确的购物篮分析等你应该怎么选择监督学习和无监督学习?在制造业中,哪种机器学习方法最适合给定的任务受着有许多因素的影响。而且,由于每个机器学习问题都是不同的,决定使用哪种技术是一个复杂的过程。一般来说,磨练正确机器学习方法的一个好策略是:评估数据。它有标签吗?是否有专家知识支持附加标签?这将有助于确定是否应使用有监督、无监督、半监督或强化的学习方法明确目标。这个问题是反复出现的吗?或者,该算法是否有望预测新的问题?回顾在维数(特征、属性或特征的数量)方面可能适合该问题的现有算法。候选算法应该适合整个数据量及其结构研究算法类型在相似问题中的成功应用最后的话监督学习和非监督学习是机器学习领域的关键概念。在学习不同的机器学习算法之前,对基础知识的正确理解是非常重要的。

 分享
分享








最新活动更多
-
3月27日立即报名>> 【工程师系列】汽车电子技术在线大会
-
即日-4.22立即报名>> 【在线会议】汽车腐蚀及防护的多物理场仿真
-
4月23日立即报名>> 【在线会议】研华嵌入式核心优势,以Edge AI驱动机器视觉升级
-
4月25日立即报名>> 【线下论坛】新唐科技2025新品发布会
-
在线会议观看回放>>> AI加速卡中村田的技术创新与趋势探讨
-
即日-5.15立即报名>>> 【在线会议】安森美Hyperlux™ ID系列引领iToF技术革新




-
10 AI时代,车企营销大变天



发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论