









斯坦福团队抄袭国产AI开源模型
01
近日,斯坦福大学AI团队主导的Llama3-V开源模型被证实套壳抄袭国内清华与面壁智能的开源模型“小钢炮”MiniCPM-Llama3-V 2.5一事,在网络上引发热议。
巧合的是,最先发现抄袭的,是星空君一起玩AI的朋友,大家先是在群里义愤填膺的批判,然后朋友把相关资料发到推特发酵,最终引起了斯坦福团队在hugging face删库跑路。

在最新进展中,斯坦福Llama3-V团队的两位作者Siddharth Sharma和 Aksh Garg在社交平台上就这一学术不端行为向面壁MiniCPM团队正式道歉,并表示会将Llama3-V模型悉数撤下。
6月3日,面壁智能CEO李大海与联合创始人刘知远先后发文,回应开源模型被斯坦福大学AI团队抄袭一事,称“深表遗憾”:一方面感慨这是一种受到国际团队认可的方式,另一方面呼吁大家共建开放、合作、有信任的社区环境。“我们希望团队的好工作被更多人关注与认可,但不是以这种方式。”
其实这从侧面反映出中国AI团队的影响力。
很长一段时间,因为圈外人难以理解的原因,中国的AI团队背负着“抄袭”、“套壳”的恶名,甚至很多人说“国外一开源,国内就自研”。
ChatGPT刚刚发布的时候,国产的AI因为采用了较多的国外训练集,使用的时候存在着把用户的中文翻译成英文再和大模型交互的情况,被恶毒的攻击为套壳。
后来,当谷歌的大模型发布的时候,人们发现几乎存在着一模一样的问题,才有一部分人明白问题的根源。
在生成式AI方面,美国的团队走的确实比较快,但并不代表中国一无是处。
如果你研究近年来AI相关的论文,会发现大量的中国团队和华人散落其中。
如果把世界AI形容成十斗,美国占八斗,中国占一斗,世界其他国家分一斗。
实事求是的讲,这样的实力并不算差。中国在这次AI革命中,没有落伍,不仅跟上了,还断崖式领先第三名。
在ChatGPT推出不到一年的时候,中国的生成式AI迅速普及,除了百度的文心一言外,像Kimi、通义千问、ChatGLM都取得了不错的效果,用户反馈比较积极。
通义千问和ChatGLM都将最新进行了开源,深受广大AI爱好者的喜欢。
MiniCPM-Llama3-V 2.5 不是一个很知名的模型,被斯坦福的大学生拿去套壳。这件事有点无厘头,但也证明了用开源模型套壳这种行为实际上是行不通的,有无数种方式可以验证大模型是否自研。
当然了,也没必要把这件事扣到斯坦福大学头上,这只是一个团队部分成员的学术不端行为,不用上纲上线。
结论是给中国的AI大模型开发者们一个迟到的正名:他们没有靠套壳开源来实现自研。
02
斯坦福的团队抄袭中国团队的AI开源大模型事件后不久,快手放出了文生视频大模型:可灵。
从前期内测用户的体验来看,可灵几乎和Sora是同一级别,某些细节还优于Sora。

难能可贵的是,可灵已经开始大规模内测,而发布了小半年的Sora依然还只是PPT状态。
我一直说,中国的AI的确比美国落后,但并没有代差,且稳居第二名,遥遥领先第三名。
当可以落地的商业模式跑通的时候,中国的AI场景不会比美国少,甚至可能还更多一些。
因为中国的自媒体行业高度发达,使用AI工具创作图文、视频素材,已经开始普及。
有拿到内测账号的朋友,用之前Sora发布的提示词交给可灵生成视频,发现效果非常惊人。

从技术路线讲,现在AI技术没有太高深的技术壁垒。
OpenAI固然niubility,但他们的先发优势非常小。ChatGPT的3.5版本领先了接近一年,4.0顶多领先了半年,现在已经被各开源大模型追赶了上来。
像中国的Kimi、通义千问、ChatGLM等大模型,近期的实测效果已经不比ChatGPT4.0差。
一方面,大模型(哪怕闭源)的主体技术路线是公开的,一些独特的训练技巧,通过高强度大范围的使用,也是可以推测出来的,在此基础上进行优化,大模型就可以“奋起直追”;另一方面,大模型行业的人才流动非常频繁,也促进了技术的传播。
OpenAI共有770名员工,ChatGPT团队不足百人,博士、硕士、本科各占三分之一。
随着追赶的加速,也许一个不留神,就有大模型实现对ChatGPT的“弯道超车”。
像传统工业时代动辄领先十数年、数十年的技术,在AI时代是不存在的。
由于字节、小红书之前过于招摇,大家几乎忘记了快手的存在。
这类短视频企业最大的优势就是有海量的音视频素材,可以方便的进行训练,而我坚持认为AI大模型本身没有什么高深的科技,无非就是大力出奇迹。
事实证明也是如此。ChatGPT3.5一炮走红的时候,人们发现原来居然可以搞一万张显卡来训练,放在其他公司这只能是想想。但模式一旦跑通,各大佬纷纷下场抢购显卡。
比较搞笑的是,可灵迅速在推特火了起来,但快手相关的APP并没有纯英文版,很多老外在推特上咨询如何注册、申请内测资格。

这也让中国的AI技术反向输出了一把。
星空君的申请只等待了一天就顺利通过,请欣赏星空君用可灵制作的视频:
提示词:一艘巨大的火箭从山谷里缓缓起飞,漫山遍野的桃花。
提示词:一个披肩发女孩站在闪耀的银河下。
提示词:宇航员走出太空船,面临一个冰天雪地的星球。
提示词:一直正在大海边弹吉他的大熊猫。
03
6月7日凌晨0点,阿里云通义千问深夜发布技术博文,推出全球性能最强的开源模型Qwen2-72B,性能超过美国最强的开源模型Llama3-70B。
两小时后,全球最大开源社区Hugging Face的联合创始人兼首席执行官克莱门特·德朗格宣布,Qwen2-72B冲上HuggingFace 开源大模型榜单Open LLM Leaderboard第一名,全球排名最高。

相比2月推出的通义千问Qwen1.5,Qwen2实现了整体性能的代际飞跃。通义千问Qwen2系列模型大幅提升了代码、数学、推理、指令遵循、多语言理解等能力。
通义千问团队在技术博客中披露,Qwen2系列包含5个尺寸的预训练和指令微调模型,Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B,其中Qwen2-57B-A14B为混合专家模型(MoE)。
Qwen2所有尺寸模型都使用了GQA(分组查询注意力)机制,以便让用户体验到GQA带来的推理加速和显存占用降低的优势。
阿里在AI方面布局非常广阔,星空君甚至认为在AI创新领域,阿里要比OpenAI更有钱景:阿里的AI研发是直接对接商业模式的,OpenAI的核心技术,在阿里这里几乎都是开源的!
就像导航软件,未来极有可能出现OpenAI的核心技术想要拿来卖钱,却发现阿里出的都是免费的。
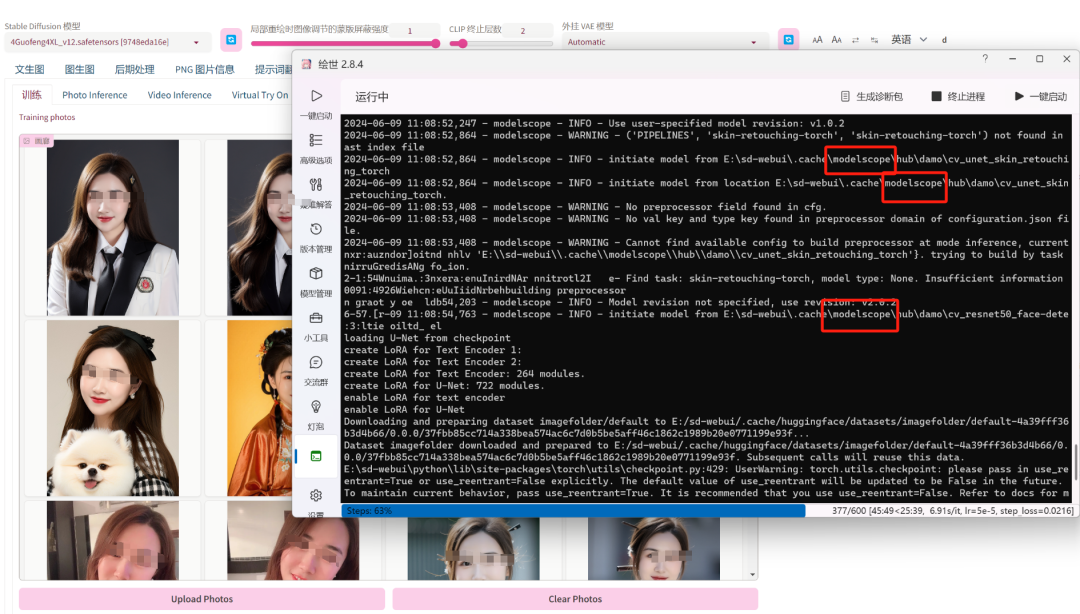
比如星空正在用EasyPhoto开源组件(EasyPhoto团队也是阿里注资的)帮朋友训练的AI绘画模型,代码里用到的modelscope是阿里的魔搭社区,阿里的很多AI领域的工作,已经成为开源界的标准之一。魔搭社区也是国内最活跃的AI开源社区,大部分开源模型都能在这里交流。

正在用ChatGLM开源模型做财经数据训练的星空君表示,之前的工作白费了,后面切到Qwen2。
冷/热知识,国内不能直接访问HuggingFace.co,可以通过镜像hf-mirror.com 访问。
说起开源,感谢马斯克,哦,不,马云开源!
原文标题 : 斯坦福团队抄袭国产AI开源模型

 分享
分享








最新活动更多
-
3月27日立即报名>> 【工程师系列】汽车电子技术在线大会
-
4月1日立即下载>> 【村田汽车】汽车E/E架构革新中,新智能座舱挑战的解决方案
-
即日-4.22立即报名>> 【在线会议】汽车腐蚀及防护的多物理场仿真
-
4月23日立即报名>> 【在线会议】研华嵌入式核心优势,以Edge AI驱动机器视觉升级
-
4月25日立即报名>> 【线下论坛】新唐科技2025新品发布会
-
5月15日立即下载>> 【白皮书】精确和高效地表征3000V/20A功率器件应用指南







发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论