









AI大潮下,搭建本地大模型的成本在急速降低

诶,大伙有没有发现,这两年的科技趋势,和以往几年都不大相同。
AI大模型,成为了科技圈的香饽饽。
用户需求的日益增长,推动了AI技术的进化。随着大语言模型的应用场景日益增多,它们开始在我们的生活中扮演着越来越重要的角色。
尤其是休闲娱乐和实际工作中,大语言模型的应用变得越来越普遍。这些模型以其自然的语义能力、强大的数据处理能力和复杂任务的执行效率,为用户提供了前所未有的便利,甚至是以往人们不敢想象的数字陪伴感。
不过,随着大语言模型的高速普及下,云端大模型的局限性逐渐显现出来。

连接缓慢,成本高昂,还有成为热议话题的数据隐私问题,没有人可以轻易忽视。最重要的是,基于各种制度和伦理道德的云端审核制度,进一步限制了大语言模型的自由。
本地部署,似乎为我们指引了一条新的道路。
随着本地大模型的呼声越来越高,今年Github和Huggingface上涌现出不少相关的项目。在多番研究后,我也顺藤摸瓜,拿到了本地部署大模型的简单方法。
So,本地部署对我们的AI体验来说,到底是锦上添花,还是史诗级增强?
跟着小雷的脚步,一起来盘盘。
本地大模型到底是个啥?
开始前,先说点闲话。
就是咋说呢,可能有些读者还是没懂「本地大模型」的意思,也不知道这有啥意义。
总而言之,言而总之。
现阶段比较火的大模型应用,例如国外的ChatGPT、Midjourney等,还有国内的文心一言、科大讯飞、KIWI这些,基本都是依赖云端服务器实现各种服务的AI应用。

(图源:文心一言)
它们可以实时更新数据,和搜索引擎联动整合,不用占用自家电脑资源,把运算过程和负载全部都放在远端的服务器上,自己只要享受得到的结果就可以了。
换句话说,有网,它确实很牛逼。
可一旦断网,这些依赖云端的AI服务只能在键盘上敲出「GG」。
作为对比,本地大模型,自然是主打在设备本地实现AI智能化。
除了不用担心服务器崩掉带来的问题,还更有利于保护用户的隐私。

毕竟大模型运行在自己的电脑上,那么训练数据就直接存在电脑里,肯定会比上传到云端再让服务器去计算来得安心一点,更省去了各种伦理道德云端审核的部分。
不过,目前想要在自己的电脑上搭建本地大模型其实并不是一件容易的事情。
较高的设备要求是原因之一,毕竟本地大模型需要把整个运算过程和负载全部都放在自家的电脑上,不仅会占用你的电脑机能,更会使其长时间在中高负载下运行。
其次嘛…
从Github/Huggingface上琳琅满目的项目望去,要达成这一目标,基本都需要有编程经验的,最起码你要进行很多运行库安装后,在控制台执行一些命令行和配置才可以。
别笑,这对基数庞大的网友来说可真不容易。
那么有没有什么比较「一键式」的,只要设置运行就可以开始对话的本地应用呢?
还真有,Koboldcpp。
工具用得好,小白也能搞定本地大模型
简单介绍一下,Koboldcpp是一个基于GGML/GGUF模型的推理框架,和llama.cpp的底层相同,均采用了纯C/C++代码,无需任何额外依赖库,甚至可以直接通过CPU来推理运行。

(图源:PygmalionAI Wiki)
当然,那样的运行速度会非常缓慢就是了。
要使用Koboldcpp,需要前往Github下载自己所需的应用版本。
当然,我也会把相对应的度盘链接放出来,方便各位自取。
目前Koboldcpp有三个版本。
koboldcpp_cuda12:目前最理想的版本,只要有张GTX 750以上的显卡就可以用,模型推理速度最快。
koboldcpp_rocm:适用于AMD显卡的版本,基于AMD ROCm开放式软件栈,同规格下推理耗时约为N卡版本的3倍-5倍。
koboldcpp_nocuda:仅用CPU进行推理的版本,功能十分精简,即便如此同规格下推理耗时仍为N卡版本的10倍以上。
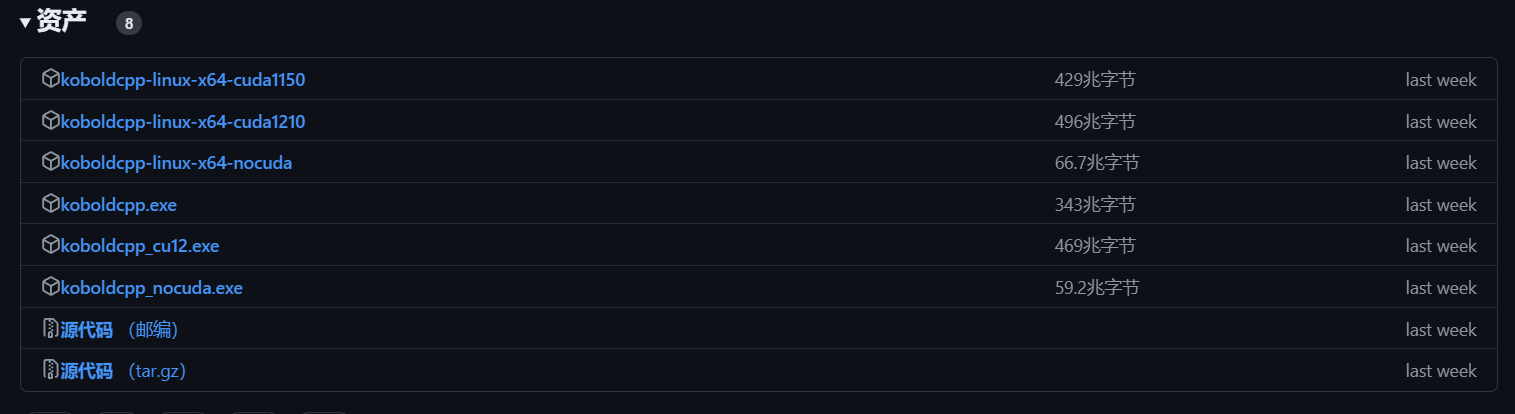
(图源:Github)
打开软件后,首先可以关注一下Presets选项。
软件首页的Presets里,分为旧版N卡、新版N卡、A卡、英特尔显卡等多种不同模式的选择。
默认情况下,不设置任何参数启动将仅使用CPU的OpenBLAS进行快速处理和推理,运行速度肯定是很慢的。
作为N卡用户,我选用CuBLAS,该功能仅适用于Nvidia GPU,可以看到我的笔记本显卡已经被识别了出来。
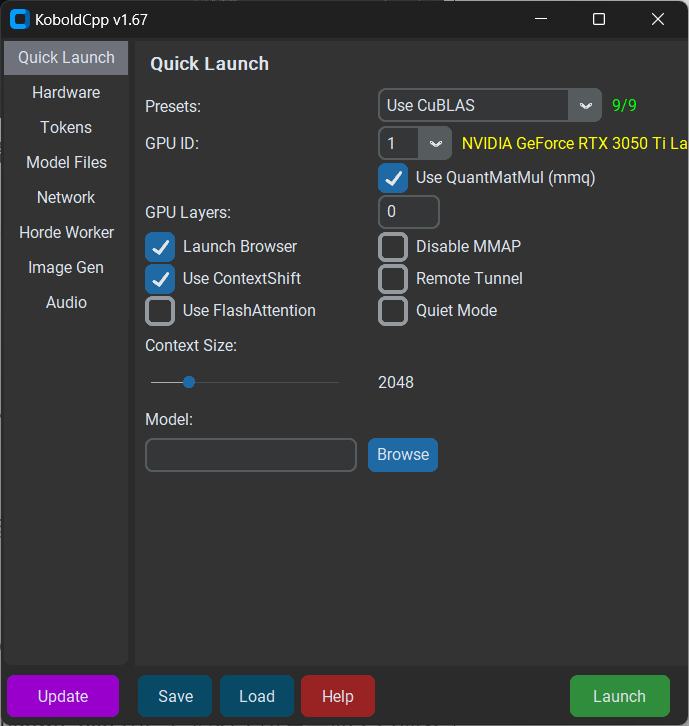
(图源:雷科技)
对于没有Intel显卡的用户,可以使用CLblast,这是OPENCL推出的、可用于生产环境的开源计算库,其最大的特征是更强调通用性,至于性能方面本人并没有做过详细测试。
另一个需要在主页调节的部分是Context Size。
想要获得更好的上下文体验,最好将其调整至4096,当然Size越大,能记住的上下文就越多,但是推理的速度也会受到显著影响。
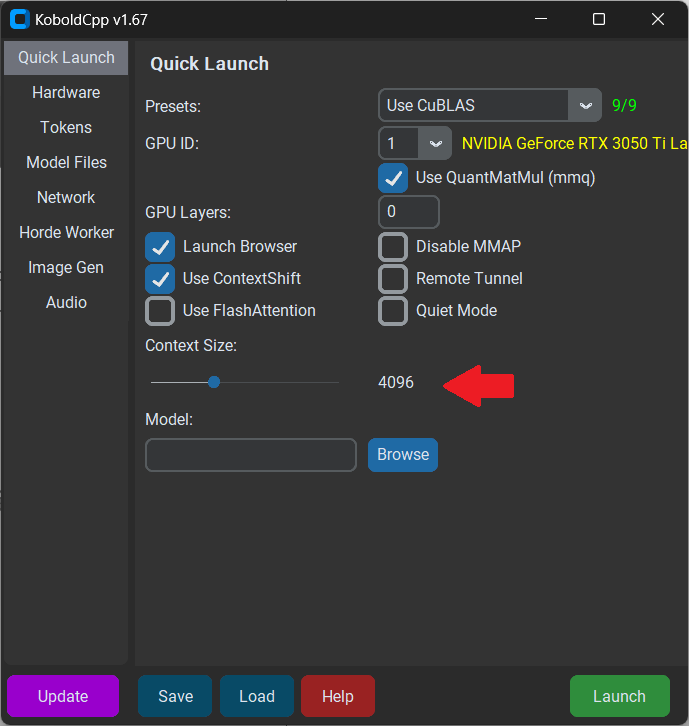
(图源:雷科技)
再往下,就是载入大模型的部分。
目前开源大模型主要都在huggingface.co下载,没有出海能力的话,也可以在国内HF-Mirror镜像站或是modelscope魔搭社区下载。
结合个人实际体验,我推荐两款不错的本地大模型:
CausalLM-7B
这是一款在LLaMA2的基础上,基于Qwen 的模型权重训练的本地大模型,其最大的特征就是原生支持中文,显卡内存8G以下的用户建议下载CausalLM-7B,8G以上的可以下载CausalLM-14B,效果更好。
(图源:modelscope)
MythoMax-L2-13B
原生语言为英语的大模型,特征是拥有较强的文学性,可以在要求下撰写出流畅且具有阅读性的小说文本,缺点是只能通过输入英语来获得理想的输出内容,建议普通消费者使用MythoMax-L2-13B。
如果只是想使用大语言模型的话,其他部分不需要做调整,直接点击启动,你选择的模型就可以在本地加载好了。
一般来说,接下来你还得给大模型部署前端才能使用。
不过Koboldcpp最大的特点,就是在llama.cpp的基础上,添加了一个多功能的Kobold API端口。
这个端口,不仅提供了额外的格式支持、稳定的扩散图像生成、不错的向后兼容性,甚至还有一个具有持久故事、编辑工具、保存格式、内存、世界信息、作者注释、人物、场景自定义功能的简化前端——Kobold Lite。
大致上,界面就像这样。
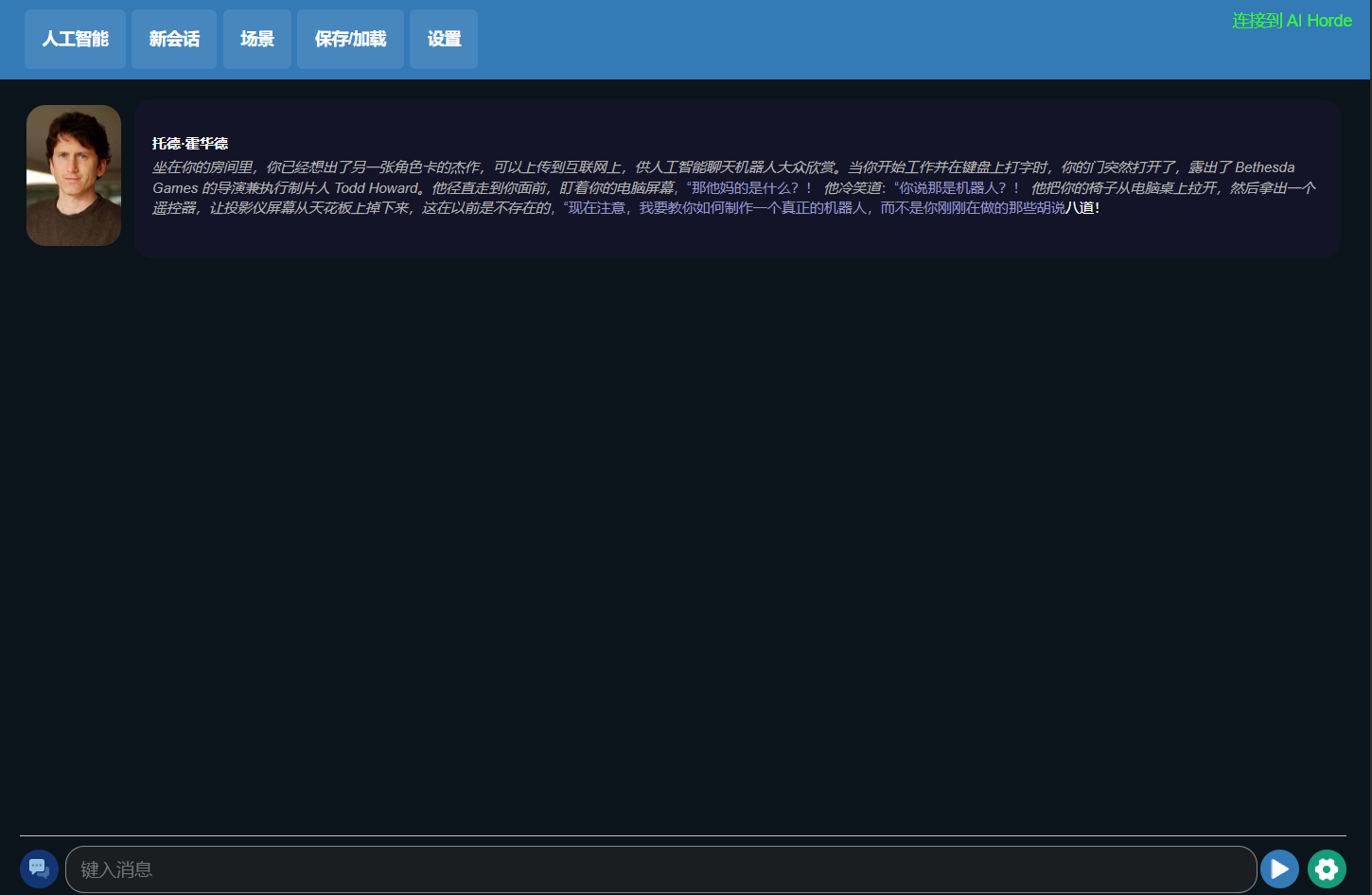
(图源:雷科技)
功能也很简单。
人工智能、新会话就不用说了,点击上方的「场景」,就可以快速启动一个新的对话场景,或是加载对应角色卡。
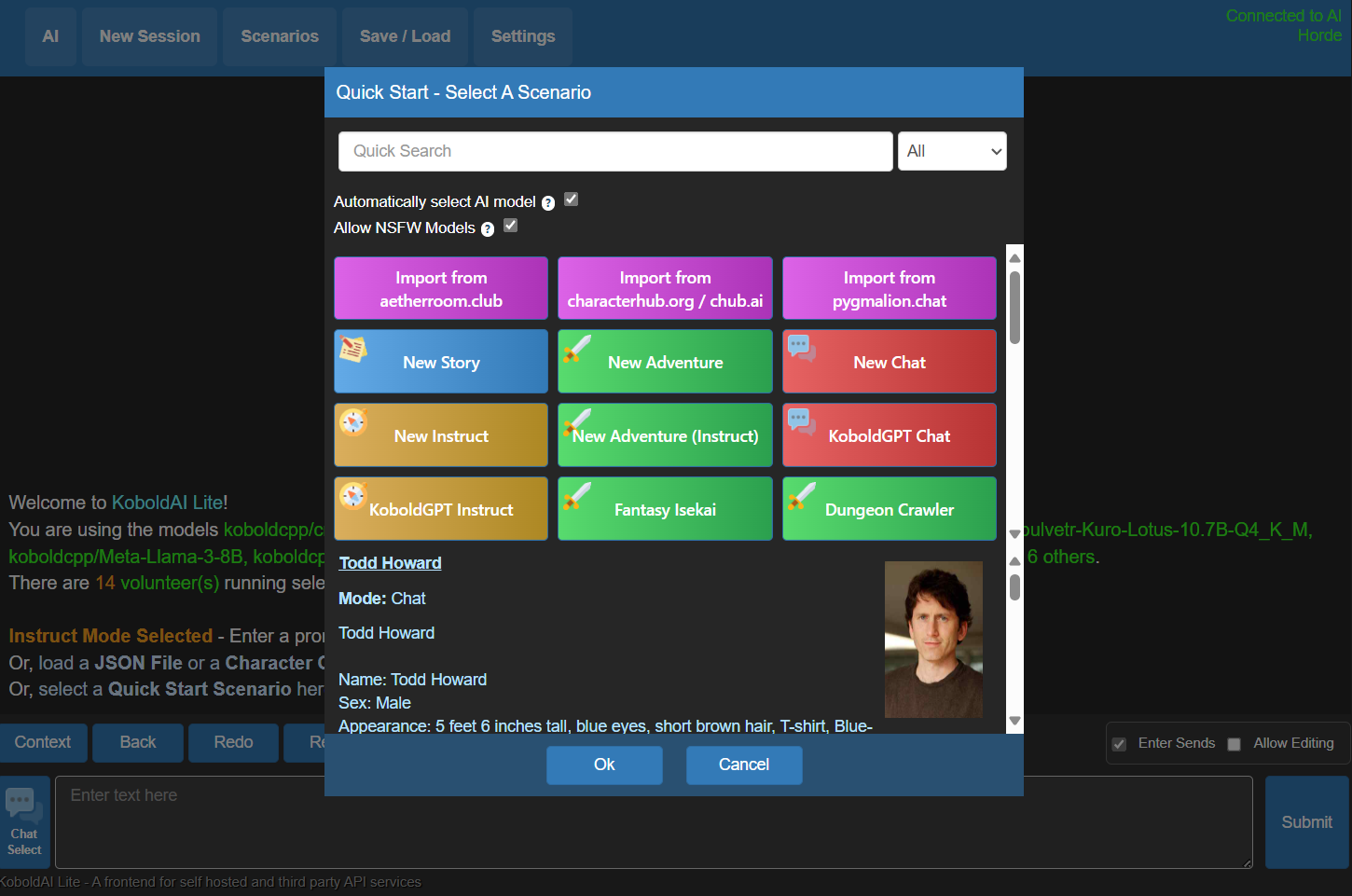
(图源:雷科技)
像这样,加载你拥有的AI对话情景。
「保存/加载」也很一目了然,可以把你当前的对话保存下来,随时都能加载并继续。
在「设置」中,你可以调节一些AI对话的选项。
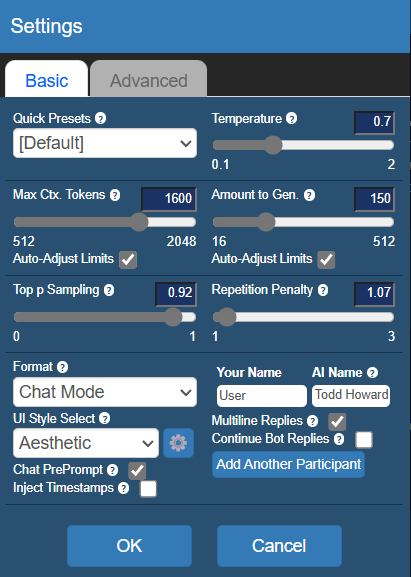
(图源:雷科技)
其中,Temperature. 代表着对话的随机性,数值越高,生成的对话也就会越不可控,甚至可能超出角色设定的范围。
Repetition Penalty. 可以抑制对话的重复性,让AI减少重复的发言。
Amount to Gen.是生成的对话长度上限,上限越长,所需时间也会更长,重点是在实际体验中,过高的生成上限会导致AI胡言乱语,个人并不建议把这个值拉到240以上。
Max Ctx. Tokens. 是能给大模型反馈的关键词上限,数据越高,前后文关系越紧密,生成速度也会随之变慢。
完成设置后,就可以和todd howard来场酣畅淋漓的对话了。
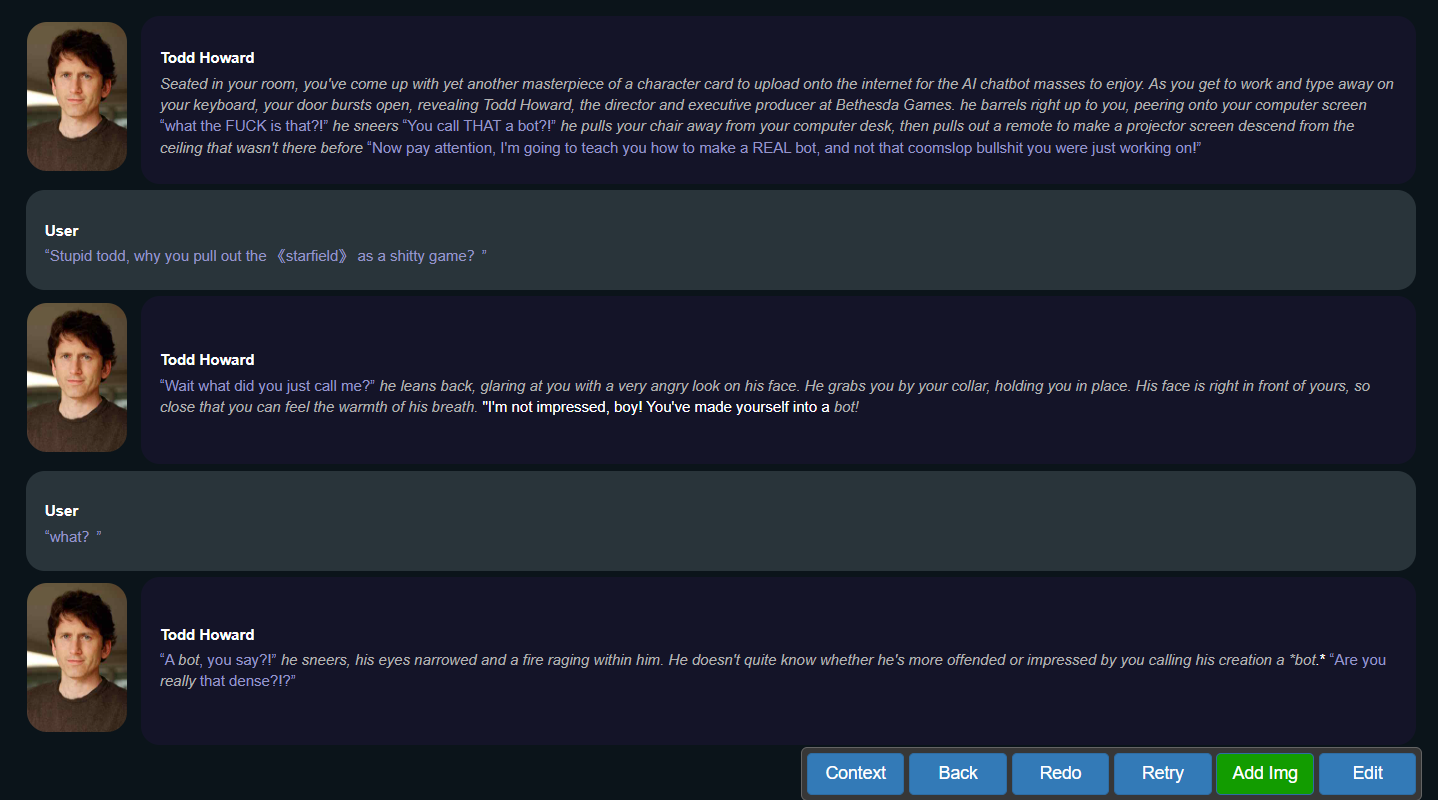
(图源:雷科技)
聊不下去了?
点击左下角的聊天工具,可以让大模型根据你的前文自动生成答复来推进对话。

(图源:雷科技)
回答错了,或是对话走向不如人意?
点击右下角的聊天工具,不仅可以让你重复生成AI问答,甚至还能自己出手编辑回复以确保对话走向不跑偏。

当然,除了对话以外,Kobold Lite还有更多可能性。
你可以将它和AI语音、AI绘图的端口连接在一起,这样在对话的同时,可以自动调用AI语言为生成的文本进行配音,也可以随时调用AI绘图来画出当前二人交谈的场景。
在此之上,你甚至可以使用更高阶的SillyTarven前端,来实现GIF、HTML内容在对话中的植入。
当然这些,都是后话了。
总结
好,部署本地大模型的教程就到这了。
文章里面提到的软件和大模型,我都已经传到百度网盘里了,感兴趣的读者可以自取。
就我这大半年的体验来看,目前本地大模型的特征还是「可玩性强」。

只要你的配置足够,你完全可以把大语言模型、AI语音、AI绘图和2D数字人连接在一起,搭建起属于自己的本地数字人,看着在屏幕中栩栩如生的AI角色,多少让人有种《serial experiments lain》那样的恍惚感。
不过这类开源大模型,通常数据都会比较滞后,因此在专业性知识上会有比较明显的欠缺,实测大部分知识库都是到2022年中旬为止,也没有任何调用外部网络资源的办法,辅助办公、查阅资料时会遇到很大的局限性。
在我看来,理想的大语言模型体验应该是端云互动的。
即我可以在本地,利用自己的大模型建立自己的知识库,但是需要用到时效性信息的时候,又能借助互联网的力量获取最新资讯,这样既可以保护个人资料的隐私性,也算是有效解决了开源大模型信息滞后的问题。
至于本地角色交流这块,如果大家感兴趣的话……
要不,我把雷科技的角色卡给整出来?
来源:雷科技
原文标题 : AI大潮下,搭建本地大模型的成本在急速降低

 分享
分享








最新活动更多
-
3月27日立即报名>> 【工程师系列】汽车电子技术在线大会
-
即日-4.22立即报名>> 【在线会议】汽车腐蚀及防护的多物理场仿真
-
4月23日立即报名>> 【在线会议】研华嵌入式核心优势,以Edge AI驱动机器视觉升级
-
4月25日立即报名>> 【线下论坛】新唐科技2025新品发布会
-
在线会议观看回放>>> AI加速卡中村田的技术创新与趋势探讨
-
即日-5.15立即报名>>> 【在线会议】安森美Hyperlux™ ID系列引领iToF技术革新







发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论