



爬虫
-

如何用Python网络爬虫获取头条所有好友信息?
前言大家好,我是黄伟。今日头条我发觉做的挺不错,啥都不好爬,出于好奇心的驱使,小编想获取到自己所有的头条好友,看似简单,那么情况确实是这样吗,下面我们来看下吧。项目目标获取所有头条好友昵称项目实践编辑
-

关于Scrapy爬虫项目运行和调试的小技巧(上篇)
扫除运行Scrapy爬虫程序的bug之后,现在便可以开始进行编写爬虫逻辑了。在正式开始爬虫编写之前,在这里介绍四种小技巧,可以方便我们操纵和调试爬虫。
-

关于Scrapy爬虫项目运行和调试的小技巧(下篇)
前几天给大家分享了关于Scrapy爬虫项目运行和调试的小技巧上篇,没来得及上车的小伙伴可以戳超链接看一下。今天小编继续沿着上篇的思路往下延伸,给大家分享更为实用的Scrapy项目调试技巧。
-
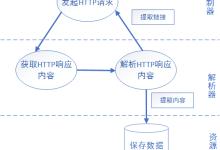
深挖网络爬虫技术及Crawl4J应用
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
-

5个用python编写非阻塞web爬虫的方法
大家在读爬虫系列的帖子时常常问我怎样写出不阻塞的爬虫,这很难,但可行。通过实现一些小策略可以让你的网页爬虫活得更久。那么今天我就将和大家讨论这方面的话题。
相关标签
![]() 换一批
换一批
最新活动更多 >
-
即日-4.22立即报名>> 【在线会议】汽车腐蚀及防护的多物理场仿真
-
4月23日立即报名>> 【在线会议】研华嵌入式核心优势,以Edge AI驱动机器视觉升级
-
4月25日立即报名>> 【线下论坛】新唐科技2025新品发布会
-
限时免费试用立即申请>> 东集技术AI工业扫描枪&A10DPM工业数据采集终端
-
在线会议观看回放>>> AI加速卡中村田的技术创新与趋势探讨
-
4月30日立即参与 >> 【白皮书】研华机器视觉项目召集令
最新招聘
更多




