





“计算医学”发现药物标志物,交叉团队组网药物 “北斗系统”
药物研发正面临巨大挑战,新药研发周期长(约14年)、新药研发成本居高不下(超10亿美元),上市药物九死一生(成功率不足10%)…...为了扭转颓势,预期能够降低研发成本的AI技术受到了制药行业的关注。
AI+药物研发赛道全球已有超100家企业,大多数集中在优化候选药物这一环节。不幸的是,进入临床一期候选药物数量的增加并不能直接带来上市成功率的显著提升。药企如果借力大数据和AI技术在以下几个问题上找到突破性的解决方案,将带来巨大的回报:如何提高临床试验成功率?如何提高药物的有效率?如何不断拓展适应症?能否唤回失败的药物?
这几个问题都可归结于如何找到能让人药更匹配的标志物。生物标志物用于疾病诊断、分型、分期,判断药物在目标人群的有效性和安全性,在药物开发与临床应用中的作用日益提升,被喻为药物研发漫漫征途中的“指南针”。
那么,标志物开发的现状如何?AI+大数据如何助力标志物开发?除了单分子,标志物还能以什么形式产生?
在本文中,有以下六个要点值得关注
1.单一分子生物标志物红利逐渐枯竭,基于大数据的新标志物将带来新红利;
2.从数据到标志物,存在维度诅咒、变异洪流、算力泥沼三大挑战;
3.来自中国顶尖机构的生命与计算交叉团队,潜心二十年,研发出基于计算医学的药物Pattern发现引擎;
4.渡过技术和数据积累期,药物Pattern发现引擎TD-P平台进入商业化阶段;
5.平台的最新成果,CDK4/6抑制剂在乳腺癌以外癌种中的新应用场景已经被发现;
6.实现药物研发从”三个10”到“三个5”的全面升级。
简单标志物红利枯竭,大数据中蕴藏新红利
单一分子生物标志物曾经成就过诸多的明星靶向药物。但是简单标志物红利正在逐渐枯竭。如果将药物伴随诊断的基因组学标志物的发现比喻为从树上摘桃子的话,这种通过“筛选”单个位点突变就能获得明确标志物的方式就好比摘低处的桃子,易得且成本优势明显,但毕竟这样的桃子数量有限,目前基本被摘完。
全球每年产生的生物数据总量已达EB(109G)级。随着不断下降的测序成本,多种组学数据、医学影像和临床资料在内统计的数据产出达到了10TB/人的水平。生物医学大数据已经可以完整刻画生命系统。 PubMed 数据库收录生物医学3000万篇文献,每天还有超1万篇的新提交。 利用知识、解读数据来寻找新标志物的新红利,无疑为业内带来了新期望。美国FDA肿瘤学卓越研究中心前主任曾表示,人工智能最有希望的应用之一是生物标志物的发现与开发。
从全球实践来看,国际上已经出现了几家能利用知识图谱、机器学习掌控生物医学大数据的AI公司。英国独角兽公司Benevolent AI和诺华制药公司在2019年签订了一项合作,旨在利用AI技术探索临床阶段肿瘤药物适应症和响应人群。Insilico Medicine公司通过收集大量不同年龄的健康和患病人群的多类组学数据,寻找与衰老和疾病有关的生物标记物。
从数据到标志物,逃避不开的三个门槛
有了数据就一定能发现标志物吗?
数据具有高维性和复杂性特点,要利用AI技术挖掘出新标志物仍然挑战重重:
第一,维度诅咒。数据爆炸带来了数千或数万个可检测的潜在生物标志物。传统的生物信息学工具、分析方法无法将日益增长、多样性的数据用以发现生物标志物。用上述方法筛选出的生物标志物只能代表小范围内的患者特征,在前瞻性临床试验中无法得到验证。在这种情况下,AI算法如何将生物标记信号从噪声中分离出来变得非常重要。
第二,变异洪流。通过测序技术,我们现在已经能较为清晰的看到肿瘤基因组的全貌,但是“画面”却极度混乱。每个肿瘤都包含50~100种变异,不同肿瘤又都各不相同,多数基因变异人类还不认识。但基因不是孤立作战,而是作为群体通过各种通路所形成的复杂网络系统来传递各种增殖和凋亡信号。不仅要发现单个变异,AI算法更需要从复杂的基因网络中识别标志物。
第三,算力泥沼。能否掌控算力又是下一个深具挑战的关卡。理解生物医学大数据必须利用超算。拥有算力已相对容易,社会上的超算中心、云计算中心可付费获得。但是现成的算力并不是为生物医学大数据而设计,如果处理计算密集型的算法能打100分,处理基因组数据只能打1分。如果将算力比喻为飞机,开动装载生物医学数据的飞机还得有并行优化技术来当驾驶员。具备生物医学领域知识专用并行优化技术的团队,在全球来说都是稀缺资源。
基于计算医学的药物Pattern发现引擎
在过去的二十年中,中国科学院计算技术研究所高性能计算机研究中心一直在从事“生物医学信息处理系统”的研究,在国家项目的支持下,已经在面向生物医学大数据的高性能计算处理技术、生命融合大数据分析技术方面取得了多项重大技术突破。
该中心的生命与计算交叉团队首倡“计算医学”,利用人工智能、高性能计算技术从单个基因或蛋白功能的解释转向从系统生物学,尤其是细胞信号通路的解释中挖掘Pattern级(实现某一生物性能的一组基因组成的功能模块)的新型标志物。
计算医学从全局变异角度解读数据。虽然肿瘤有很多罕见变异,但是它们驱动的下游事件并不罕见。因此,如果能构建一种新的模型,建立罕见变异与下游事件的关系,就能够破解肿瘤异质性难题,找出未被发现的肿瘤进化生物学机制,挖掘Pattern级标志物。
就像是AlphaGo,它比人类厉害的地方在于,它的算法更关注大局观,而不是局部计算。在每个局部计算中找到最优的下法并不一定能获得最终胜利,只有清晰理解全局战况,才能做出必胜策略。
这也就是团队这些年来的主要发力方向。
破解维度诅咒,将变异洪流降维到细胞功能事件模型。团队大数据建模过程与AlphaGo的算法策略异曲同工。团队根据曾发生变异的18000基因,1000种不同来源细胞系基因组内罕见变异的基因集合特征,对200+种表型特征(细胞内确定性事件集)进行关联训练,获得基于神经网络的细胞行为、功能、信号通路之间的关系模型,将零散、孤立的变异转化成有功能、有解释意义的事件。团队没有直接将基因变异与疾病建模关联,而是先降维到细胞功能事件模型,再去与疾病、药物关联,这极大提高了从数据中发现新洞见的效能。
经过数年的基础工作,团队已经产出了400+细胞内确定性事件基础模型。击败人类的围棋机器人AlphaGo面对的是19路围棋棋盘的361个落点,可以变幻出无数的棋路。同样,这400种基础模型可以组合无数种不同的肿瘤进化情况,足以为每个患者构造一个数字生命方程式。现已验证的肺癌病例中无阴性报告,整体有效率为70.6%,抗血管生成通路有效率更高达91%。

将变异数据编码为细胞功能事件
从知识中推理生物医学机制新洞见。团队根据海量的生物医学文献构建了自己的生命科学专用知识图谱TWIRLS,去发现疾病-表型-基因-蛋白-药物之间的关联。应用这一知识图谱,不仅能够最大化地挖掘已有的知识,还可以根据已有的知识做出推断,产生新知识。
在新冠疫情期间,团队在4小时内通过对1.4万多篇有关冠状病毒文献智能推理分析,最终得出病毒与ACE2之间的结合可能引发ACE2/AT2R的功能变化,使肾素——血管紧张素系统(RAS)参与的细胞因子调控轴发生稳态失衡,并最终导致“细胞因子风暴”的结论。团队认为这可能是参与冠状病毒感染后导致宿主病理性变化的重要调控因素,也得到了国内三家权威机构回顾性研究的确认。该研究最近发表于《DRUG DEVELOPMENT RESEARCH》期刊。
大幅提速数据处理效能的高性能计算。团队拥有世界领先的并行优化算法,在训练模型阶段,团队用到了106G的数据,调动 2000个CPU运行半年。如果没有并行优化技术,即使历时数年也可能跑不出结果。对同一模型、同一数据量处理,如果直接在小型机上计算需要1万小时,加载并行优化技术后,计算时间可压缩到100小时。高水平的并行优化团队还能再获得更大的效率收益。
渡过技术和数据积累期,TD-P平台开放商业化服务
基于计算医学的药物Pattern发现引擎是否还是一个科研阶段,能提供商业化解决方案吗?
为了将“生物医学信息处理系统”赋能产业,中科院计算所孵化了哲源科技,对其研究成果进行转化,并联合成立了“中国科学院计算技术研究所·哲源-图灵-达尔文实验室”,致力于计算医学的发展,通过药物Pattern发现引擎TD-P平台(Turing-Darwin Pattern Discovery Platform)赋能药物研发、精准医学。该平台已经渡过了技术积累和数据积累期,具备了工业化服务能力。
第一,标志物兼容性好。基于TD-P平台不仅可以发现定量性质的,具有生物学意义的新型标志物,同时也能向下兼容单分子生物标志物。例如,该平台与国内著名PI在某一实体肿瘤化疗药物适应人群判断的合作中,最终收敛出能够被PCR技术检测的变异位点,质优价廉,为IVD行业带来全新解决方案。
第二,迅捷解决临床问题。针对某一特定药物研发与临床应用场景需求,只需要投入较少量的指定样本数据在该技术平台适配,即可以周为单位交付初步发现的标志物。然后利用后续患者数据在该模型中做进一步前瞻性预测,优化模型精准度。同样在上述案例中,20个样本规模即有初步发现,用预测模型对上百个前瞻性样本预测的阳性检出率达70%。
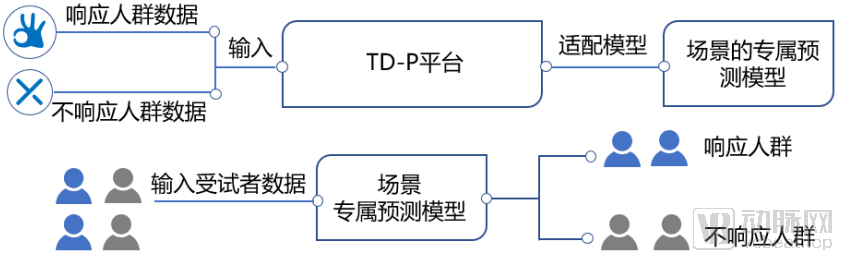
场景专属模型适配
第三,适用场景广泛。平台一体两面,为药找人,为人找药。在药物研发阶段,可以协助新药临床场景的选择、临床试验入组优化、适应症扩展、跨线晋级。在临床应用阶段,为患者匹配响应度最佳、副作用最小的用药方案,将医生临床实践中已经积累的宝贵的临床治疗方案和经验发挥到极致,实施更加精准的个体化治疗。
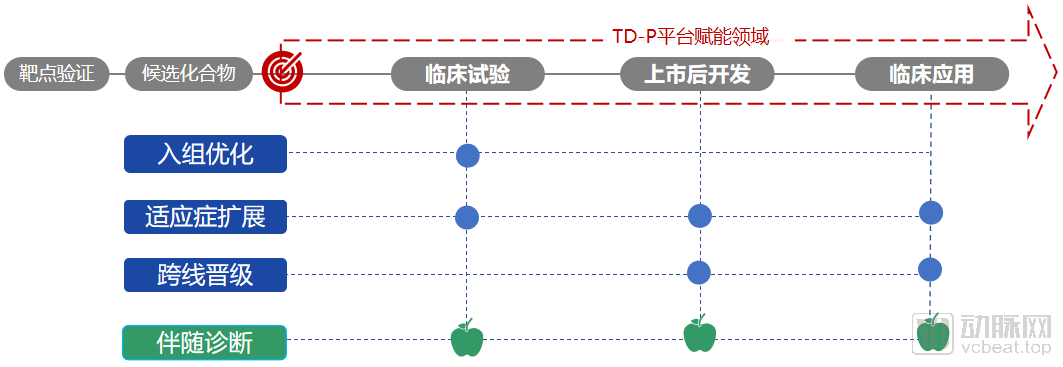
广泛的服务场景
发现CDK4/6抑制剂新场景
TD-P平台是否能为业界带来重磅惊喜?
CDK4/6抑制剂是针对CDK4和CDK6两个蛋白的靶向药物,主要应用于激素受体阳性Her2阴性的乳腺癌患者群体。首款CDK4/6抑制剂“爱博新”2019年销售额近50亿美元。多家知名企业都在布局CDK4/6抑制剂,预计国内竞争将很快达到白热化。
不过即便使用了雌激素受体作为生物标志物,仍有大约20%的患者最初不会对CDK4 / 6抑制剂产生反应,并且所有患者最终都有产生耐药性的可能。其他一些相关临床试验也曾尝试过多种不同分子标志物,都不尽人意。可以说,采用单分子作为标志物的努力基本宣告失败。谁能回答以下问题,谁就更有机会在白热化竞争的市场中胜出。
1. 是否存在标志物预测患者的药物反应?
2. 是否可与内分泌疗法以外的其他疗法结合使用?
3. 是否可将适应症扩大到其他癌种?
TD-P平台在对CDK4/6抑制剂以往的研究数据和临床情况分析后,已经发现几个其他癌种的患者同样能从CDK4/6抑制剂中获益,疗效甚至可能优于乳腺癌患者。哲源科技也希望能与CDK4/6抑制剂研发企业合作这一自有成果。TD-P平台还在抗血管药物、PD-1/PD-L1单抗等抗肿瘤药物的伴随诊断开发、全新临床场景挖掘、临床试验入组优化方面有突破性发现。
从”三个10”到“三个5”
中国科学院计算技术研究所西部高等技术研究院常务副院长张春明向动脉网表示:“我们希望利用紧贴临床的人工智能加速药物研发,大幅降低研发费用。将十年研发周期、十亿美金投入、10%临床试验成功率的‘三个10’研发挑战,提高到‘三个5’,即5年研发、5亿美金、50%的临床试验成功率。”
利用大数据、人工智能、高性能计算组网的药物研发与应用的“北斗系统”为面临困局的医药行业开启了药物精准定位的新时代。制造出药物已经不是竞争的终点,提速临床试验、不断拓展新适应症、为患者提供更精准响应的药物、更好地利用真实世界数据才是未来的竞争制胜之道。“计算医学”从数字生命的视角认识疾病与药物,协助开发特异性、有效性、安全性更好的药物,带来更精准的“人药匹配”,将会带动医药行业新一轮的智能化升级。
作者:郝翰

 分享
分享
图片新闻








技术文库
最新活动更多
-
4月23日立即报名>> 【在线会议】研华嵌入式核心优势,以Edge AI驱动机器视觉升级
-
4月25日立即报名>> 【线下论坛】新唐科技2025新品发布会
-
7.30-8.1火热报名中>> 全数会2025(第六届)机器人及智能工厂展
-
7月30-31日报名参会>>> 全数会2025中国激光产业高质量发展峰会
-
精彩回顾立即查看>> OFweek 2025(第十四届)中国机器人产业大会
-
精彩回顾立即查看>> 【在线会议】从直流到高频,材料电特性参数的全面表征与测量



发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论