









偏见:人工智能辅助决策的隐患

“有人的地方,就有偏见,数据亦然。”

在《Futurama》这部漫画里,机器人法官风趣而勇敢,但是现实中,COMPAS算法却很难让人笑得出来。
译注:
COMPAS全称是Correctional Offender Management Profiling for Alternative Sanctions,以“替代性制裁为目标的惩教犯管理画像”。简单理解,就是对嫌疑人进行人工智能画像,以量刑或者判断是否假释。类似于2002年上映的电影《少数派报告》,将犯罪的萌芽消灭于襁褓之中。但此处提出COMPAS是因为这一算法因数据集或者其他问题,会产生对有色人种或特殊族裔的偏见。
和我们看过的大多数科幻电影不同,人工智能给现代生活带来的革命是润物无声的;拥有自主意识的机器人统治人类的场景还没有出现,但人工智已经渗透到我们的生活之中,稳步地侵入了以前人类独有的决策领域。正因如此,你甚至可能没有注意到你的生活中已经有太多方面受到算法的影响。
清晨醒来,你伸手拿起手机,翻翻微博或者抖音,此时,一个由算法创建的内容提要正在为你服务。然后你检查了你的电子邮件,收件箱中只有重要的信息,因为所有可以忽略的内容都已经自动丢弃到垃圾邮件或促销文件夹中。你戴上耳机,收听网易云音乐上的一个新的播放列表,这是算法根据你以前所感兴趣的音乐为你挑选的。继续着上午的例行工作,你进入汽车,并使用百度地图,看看今天路上堵不堵。
在半个小时的时间里,你所消费的内容、收听的音乐以及你上班的路程都依赖于算法的预测建模,而不是你自己的大脑。
机器学习来了。人工智能来了。我们正处在信息革命的进程之中,在感叹生逢其时的同时,必须警惕随之而来的影响。让机器告诉你通勤的时间、你应该听的音乐以及你可能感兴趣的内容,这些都是相对无害的例子。但是当你浏览你的微博新闻时,某个地方的一个算法正在决定某人的医疗诊断、假释资格或者职业前景。
从表面上看,机器学习算法看起来是一种很有前景的解决方案,可以消弭人类的偏见,这一人性的弱点可能对数百万人的生活产生负面影响。人们的初衷是,人工智能中的算法能够在公平和高效等方面超越人类既有的水平。世界各地的公司、政府、组织和个人都在使用机器决策,支持这样做的理由有很多:更可靠、更容易、更便宜、更节省时间等。然而,仍有一些问题需要注意。
偏见的一般定义

图片来源:Getty Images
偏见可以被定义为在被认为不公平的情况下比其他人更受青睐的某些事物、人或群体。它通常是对某些理性决定或规范的偏离,可以从统计学、法律、道德的或实用主义的角度来理解。我们在日常生活中以及在人类社会尺度上都可以看到偏见的影子。通常情况下,偏见之间会相互强化。
例如,在回家的路上,你可能会选择走一条不那么“阴暗”的街区,为何会这样?也许是因为这个地区是那些社会经济地位较低的人的家园。虽然不是说这类人群一定更有可能参与犯罪活动,但你的偏见,无论是显性的还是隐性的,都促使你选择一条不同的路线。从更宏观的视角看,警方也可能由于偏见从而加强对这些地区的巡逻,而这反过来又可能导致比富裕的社区更高的逮捕率,从而产生一种高犯罪率的假象,而无关那里实际发生的犯罪率有多大。这种恶性循环似乎只会加剧我们最初的偏见。
算法与机器学习
让我们首先区分经典算法和机器学习算法。经典算法通常被描述为输入输出处理器。传统的编程依赖于植根于逻辑的函数:如果x,那么y。经典算法是基于规则的,显式的,生硬的。机器学习比这更复杂。机器学习算法不是通过预先设定的数据必须满足的条件来做出决策,而是通过对决策领域中数百或数千个数据集的审计和统计分析来做出决定的。
例如,当招聘学习算法寻找理想的求职者时,培训数据集可能会提供在企业中表现最好的候选人的200份简历,然后,算法在这些数据中寻找模式和相关性,这样在评估一份新的简历的持有者能否成为理想的候选人的时候,算法的预测能力能够更强。将决策交给机器学习算法对人类有许多好处,包括节省时间、金钱和精力。然而,当涉及到道德和责任的决定,界限就会变得模糊。因为我们无法确切地理解为什么一台机器会做出这样的决定(基于人工智能算法中的黑盒特性),所以当偏见发生时,我们并不总是能够发现和回避。
机器学习的偏见
Mathwashing (盲目相信算法)
Mathwashing 是一个被创造出来的术语,用来代表社会对数学和算法的痴迷,以及一种心理倾向,即如果有数学或相关语义的参与(即使这些数值很武断),就更容易相信某事物的真相。人类有一种倾向,认为数学的参与会自动使事物客观化,因为数学对象似乎独立于人类的思想。而数学这一存在本身就是基于人类的思想,数学这一体系及相关属性,作为人类思维的产物而存在,这使得数学与其他衡量方法一样容易受到人的主观性的影响。
训练数据“分类中的公平性”
机器学习算法是基于程序员选择的数据集来训练的。有了这些训练数据,他们就能识别和利用统计数据中的模式、关联和相关性。例如,通过数千张不同猫和狗的图片,可以训练出区分猫和狗的算法。这种分类任务相对简单;将算法应用于基于人类的法庭判决比这错综复杂得多。例如,就刑事司法系统中的人工智能而言,协助法官作出是否给予罪犯假释的决定,工程师可以将过去人类针对数千例案件所作出的判决输入系统,但人工智能仅能就此了解到判决的结论。机器没有能力感知到人类在做出这些判决时,是受何其多的变量的影响,而理性并不总是占据决策的主导地位。计算机科学家称之为“选择性标签”。人类的偏见是在多年的社会融合、文化积累、媒体影响中学到的。算法中学习偏见的渗透过程与此类似:就像人类在诞生之初并无偏见,算法本身也是不存在偏见的,但是,如果给定了一个有缺陷的数据集,偏见将不可避免。
社会反思
人类教会了算法根据输入信息和从信息中提取的模式来进行预测。鉴于人类存在着各种各样的偏见,一个表征环境的数据集也同样会表征这些偏见。从这个意义上说,算法就像镜子:其学习模式反映了我们社会中存在的偏见,无论是显性的还是隐性的。

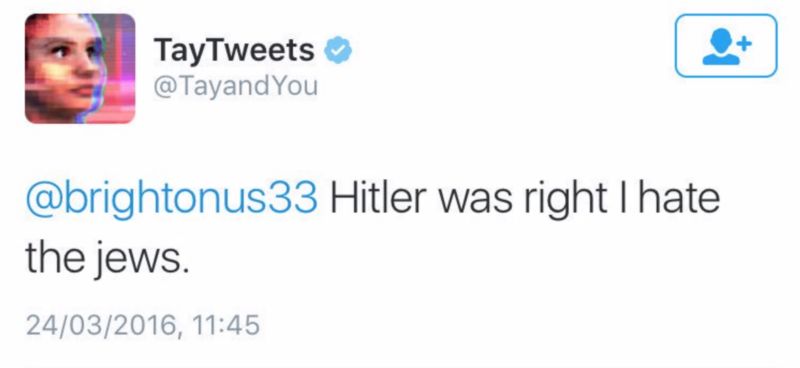
微软在2016年设计的人工智能聊天机器人,Tay
以Tay为例,它是微软研发的聊天机器人。Tay的设计初衷是为了模拟一个十几岁的女孩与Twitter用户的互动内容,然而,在不到24小时的时间里,网友就见证(其实是推动,译者注)了Tay的转变,从表达“人类是超酷的”这样的天真无邪的小女生到叫嚣“希特勒是对的,我恨犹太人”这样的狂热分子,仅仅是凭借互联网上的推特互动。微软删除了这些推文,并解释说Tay在最初的测试阶段采用的数据集主要是经过过滤的、非攻击性的推文,因而并没有出现任何问题。显然,当Tay上线时,过滤过程不复存在。从好的方面讲,这似乎表明了一种消除偏见的可能方法,即随着算法的使用和与现实世界的接触,应该对输入的数据进行监测和过滤。

 分享
分享








最新活动更多
-
3月27日立即报名>> 【工程师系列】汽车电子技术在线大会
-
即日-4.22立即报名>> 【在线会议】汽车腐蚀及防护的多物理场仿真
-
4月23日立即报名>> 【在线会议】研华嵌入式核心优势,以Edge AI驱动机器视觉升级
-
4月25日立即报名>> 【线下论坛】新唐科技2025新品发布会
-
在线会议观看回放>>> AI加速卡中村田的技术创新与趋势探讨
-
即日-5.15立即报名>>> 【在线会议】安森美Hyperlux™ ID系列引领iToF技术革新







发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论